The first seven chapters have been about teaching the basics of Assembly and getting output of strings and numbers to the screen. All those steps were required for learning Assembly. However, at some point, when you have a program that is meant to do something, you need to have a way for other people, especially those who are not programmers, to be able to give input to direct what the program does.
There are two main ways of doing this in a console program. The first way is have the program ask for the user to type something from the keyboard and then wait until they write something and press enter. The next program will achieve this. Copy this and try it out and then I will explain after the code how it works.
FASM Keyboard Input
format ELF executable
main:
mov dword [radix],10
mov dword [int_width],1
loop_input:
mov eax,string0
call putstring
call getstring
mov esi,eax ;mov the string address in eax to esi
mov edi,string3 ;mov the "exit" string address to edi
call strcmp ;call the function to compare the strings and return eax
cmp eax,0 ;if eax is 0, the strings are the same
jz the_end ;go to the_end if the user typed "exit"
mov eax,string1
call putstring
mov eax,buf
call putstring
call putline
mov eax,string2
call putstring
mov eax,[count]
call putint
call putline
jmp loop_input
the_end:
mov eax,1
mov ebx,0
int 80h
string0 db 'Enter a string from the keyboard: ',0
string1 db 'string: ',0
string2 db 'length: ',0
string3 db 'exit',0
buf db 0x100 dup '?'
count dd 0
getstring:
mov [count],0 ;set count of characters read during this function to zero
mov edx,1 ;number of bytes to read
mov ecx,buf ;address to store the bytes
getstring_chars:
mov ebx,0 ;read from stdin
mov eax,3 ;invoke SYS_READ (kernel opcode 3)
int 80h ;call the kernel
cmp eax,1 ;was 1 character read?
jnz getstring_end ; if not, then end this loop
mov al,[ecx] ;mov last character read into al register
;check if this character is in the proper range to be part of the string
cmp al,0x20 ;compare with 0x20 (space)
jb getstring_end ;jump if below to getstring_end label
cmp al,0x7E ;compare with 0x7E (tilde)
ja getstring_end ;jump if above to getstring_end label
;if neither jump happened, keep the character and
inc [count] ;increment how many characters we have read
inc ecx ;increment address where next byte is read from
jmp getstring_chars ;jump back to start of loop and keep reading
getstring_end:
mov byte[ecx],0 ;terminate this string with a zero
mov eax,buf ;mov the buffer address to eax for returning the string
ret
;strcmp compares the string at esi to the one at edi
;eax returns 0 if the strings are the same and 1 if different
;the algorithm is simple but I will explain it for those who are confused
;eax is initialized to zero
;a byte from each string is loaded into the al and bl registers
;the bytes are compared. if they are different, then we jump to the end
;However, if they are the same, then we check if one of them is zero
;for this purpose it doesn't matter whether we compare al or bl with zero
;because it is known that they are the same if the jnz did not take place
;if it is zero, this also jumps to the end of the function
;If neither jump took place, then we jump to the start of the loop
;but when the function finally ends bl will be subtracted from al
;this ensures that the function returns zero if the final characters are the same
strcmp:
mov eax,0
strcmp_start:
;read a byte from each string
mov al,[edi]
mov bl,[esi]
cmp al,bl
jnz strcmp_end
cmp al,0
jz strcmp_end
inc edi
inc esi
jmp strcmp_start
strcmp_end:
sub al,bl
ret
include 'chastelib32.asm'
The getstring function uses a read system call to read from file descriptor 0 which represents standard input or the keyboard. It reads one character each time with a loop and starts at an address labeled “buf” which was declared as a global variable of 256 bytes which were initialized with question marks. I also defined a variable named count which was used to automatically count how many bytes were read.
buf db 0x100 dup '?'
count dd 0
But I feel that the part of this function that needs the most explaining is this section:
cmp al,0x20 ;compare with 0x20 (space)
jb getstring_end ;jump if below to getstring_end label
cmp al,0x7E ;compare with 0x7E (tilde)
ja getstring_end ;jump if above to getstring_end label
Because this range of characters from space to tilde is what I have identified as the acceptable range of characters. There is no standard way that makes sense for all strings. For example, someone may want to make a getstring function that only accepts capital letters or that only accepts numbers 0 to 9. I can’t say that there is one way that is the best.
The program listed above will keep running the loop until the user types “exit” as the string. Each time after it gets the string, it compares the what the user entered to the “exit” string. If the strcmp function returns 0, it means the two strings are the same.
This particular variant of strcmp is based off of the C function of the same name. You may also remember that I wrote a strlen function for the first example in chapter 7 when I had a string that I wanted to write to a new file.
I believe that using conventional names of C functions is a good idea because C programmers who read my books will already be familiar with that function and what it does in the C programming language.
In any case, “exit” was the perfect name for a command to “exit” the program. It is also how you log out of a Linux terminal and is the official name for the system call that exits every program in this book!
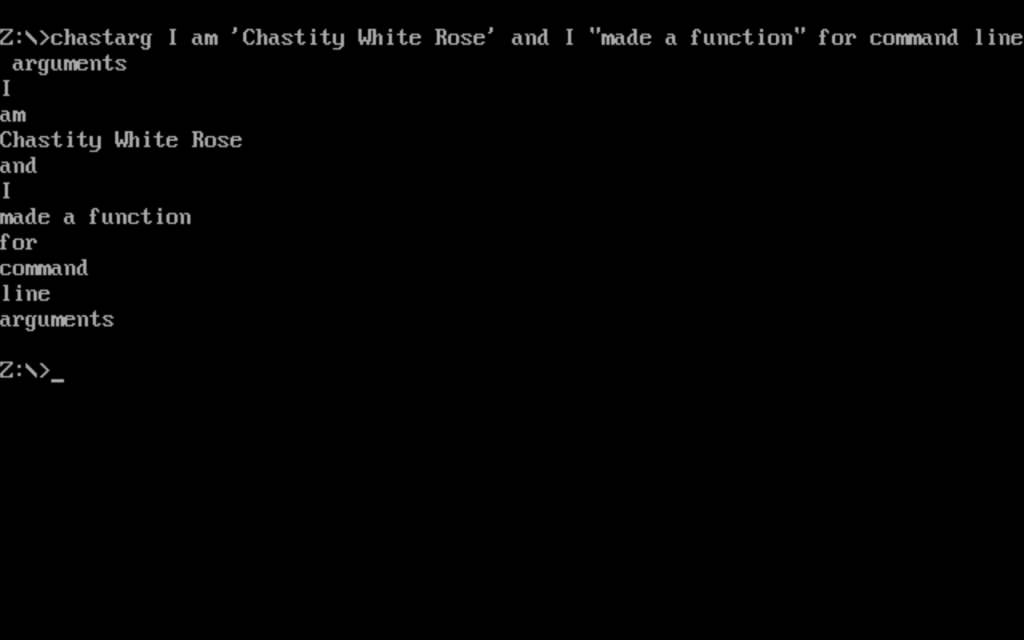
Although using the keyboard for input during a running program is a great interactive way of doing things, there is one way that I enjoy even more. The next program is one that I wrote long before I started writing this book and has been referred to as “chastearg” on my blog and the Flat Assembler Forum. It prints the command line arguments when you add them after the name of the program.
FASM Command Line Arguments
format ELF executable
entry main
include 'chastelib32.asm'
main:
pop eax ;pop the number of arguments from the stack
mov [argc],eax ;save the argument count for later
pop eax ;pop argument 0 (name of the program)
dec [argc] ;subtract 1 from argument count
putarg:
cmp [argc],0 ;check for remaining arguments
jz putarg_end ;if none, end the loop and stop printing
pop eax ;pop the next argument off the stack
call putstring ;print the string and a new line
call putline
dec [argc] ;subtract 1 from argument count
jmp putarg ;jump to the beginning of the loop
putarg_end:
mov eax, 1 ; invoke SYS_EXIT (kernel opcode 1)
mov ebx, 0 ; return 0 status on exit - 'No Errors'
int 0x80
argc dd 0
What is a Command Line Argument?
People who come from a Windows environment may not even know what a command line argument is because they are used to pointing and clicking with a mouse. You can’t enter an argument this way. For clarification on this topic, here is some terminal text to clarify what arguments are.
fasm main.asm
flat assembler version 1.73.30 (16384 kilobytes memory)
2 passes, 481 bytes.
chmod +x main
./main this program has command line arguments
this
program
has
command
line
arguments
When we run fasm and give it the name of the Assembly file we want to assemble, the file is an argument or an option we provide to it. In the above example, main.asm is the file I provide to fasm as an argument.
After the file is assembled, I run the chmod command with the arguments “+x” and “main” which adds the execution permission to the main executable that was just created.
Finally, running “./main” followed by more words on the same line causes Linux to interpret them as arguments. They are pushed onto the stack.
When a program begins on Linux, you can access the number of how many arguments were passed to the program by getting the first number you pop off the stack. In the chastearg program, there is a loop that keeps track of how many arguments are left. While there are some remaining, it keeps popping them into the eax register and calling putstring until there are none left.
Arguments vs Keyboard Input
The primary difference between input from the keyboard during a program and passing arguments is that the arguments do not stop the execution of a program and wait for anything. If you have an install script which is meant to compile and install a large program, it is better not to pause it for any reason unless an error happens. Arguments are best in this case so that someone can pass information to it that they want the program to know.
Keyboard input does have a benefit though. For example, suppose that you ask the user to input a number and then they accidentally input a string that is not recognizable as a number. With keyboard input, you can tell them they made a mistake and ask them to try again. With arguments, you cannot edit them during the program because they are only pushed at the start when the program is run from the terminal.
Only you can decide which of these methods your program needs, but I hope that my explanation and my strcmp function is helpful for you when you try to write a program that needs input to do different things conditionally.
Later in this book, I will present a calculator written in Assembly language that builds from this chapter’s keyboard input loop. However, we are not ready for that until I teach you how to separate regular strings from numbers. That will be the subject of the next chapter and I can promise you it is simultaneously the hardest task but also the most useful feature you will need for writing any program that has to read numbers.